In today's digital society, data is often considered the fuel for any organization. Many technology-oriented organizations are involved with large-scale data collection in their research, development, and service delivery activities. Former technology policy advisor Tom Kemp states that the five major ‘Big Tech’ companies – Meta, Apple, Amazon, Microsoft, and Google – have built innovative products that improve many aspects of our lives. Big Tech’s business models are driven by more data [1], and AI-based technologies are trained and improved using high quantities of data. On the other hand, their intrusiveness and our dependence on them have created pressing threats to our civil rights, economy, and democracy. Kemp addresses two major concerns: the overcollection and weaponisation of our most sensitive data and the problematic ways Big Tech uses AI to process and act upon our data. In 2019, Financial Times journalist Rana Foroohar wrote in her book
Don’t be Evil how today’s largest tech companies are hijacking our data since they wield more power than national governments [2]. Because of their influence, Alexis Wichowski, a former press official for the US State Department during the Obama administration, has re-branded these major tech companies as ‘net states.’ With the new tech-oriented Trump administration [7], the debate about data as currency to drive economies is fired up again. Simultaneously, current and upcoming EU regulations regarding digitalisation and data processing—including the Data Act, NIS2 Directive, Cybersecurity Act, AI Act, and GDPR—contrast Big Tech's intentions. The GDPR aims to limit the processing and consumption of personal data to ensure data processing activities are proportional to their purpose or have a valid legal basis. The way we generate data nowadays is diverse, and with the use of AI this will grow significantly.
What is the problem
An increasing appetite for data has become the norm in today's data-driven world; according to Statista, 2,142 zettabytes of data will be created by 2035. The prevailing belief is that accumulating more data enables organizations to make more informed business decisions and improve their economic performance.
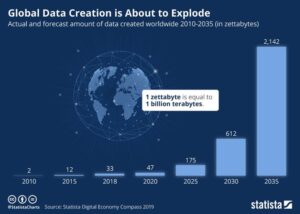 Figure 1: Global Data Creation according to Statista
taken from Statista
Figure 1: Global Data Creation according to Statista
taken from Statista
However, it is crucial to recognize that the quantity of data only sometimes equates to improving data quality. In the rush to amass vast amounts of data, organizations may inadvertently compromise the integrity and relevance of the data they collect. Additionally, such colossal datasets’ permanent or long-term storage is not always feasible or cost-effective. This leads to a new challenge: the danger of 'old' or 'forgotten' data, sometimes called 'dark data' [3]. The risks associated with these data become increasingly evident. Highlighting the risks that persist when vast amounts of data are kept, often indefinitely. Every dataset or database becomes an additional target for adversaries seeking to steal or manipulate data, putting individuals and organizations at risk. Marriott International and its subsidiary Starwood Hotels & Resorts Worldwide were
fined for millions of dollars and forced by the Federal Trade Commission (FTC) to effectuate data-minimization and deletion-practices [8].
Organizations must balance their insatiable hunger for data with the imperative of data detox to ensure that the data they collect is safe, relevant, and protected against potential breaches. The growing hunger for data results in data-obese organizations struggling to archive or destroy their (dark) data. In other words, they must follow a
data detox to become data-fit. In addition to focusing on existing data sets, organizations require a lean, future-proof approach to collecting, processing, storing, and archiving data, requiring a
data diet to remain data-fit. This brings us to present the following problem statement:
Modern organizations' proliferation of data collection practices raises a critical challenge. Pursuing extensive data repositories may increase the organization's attack surface complexity while simultaneously introducing legal and reputational risks related to data loss or theft. This article investigates the delicate balance between data collection ambitions and the imperative of safeguarding data privacy and protection, aiming to provide insights and practices that can guide organizations in effectively mitigating these inherent risks. To quote Bruce Schneier:
“Data is the pollution problem of the information age, and protecting privacy is the environmental challenge.” [4]
Expert panel
The expert panel research was conducted with seven experts. They represented a variety of expertise fields and a combined 120 years of relevant experience.
Results of our research
The expert panel identified several points of attention and ranked them based on priority for implementation.
Data detox to become data-fit
The expert panel identified twelve points of attention regarding data detox that were subsequently evaluated and prioritised, resulting in the following main findings:
1.
Prioritise data retention for data with so-called ‘high toxicity.’ Typical examples include personal data, health data, intellectual property data, and information related to national intelligence and security matters. This data type is typically of high value for involved organizations and society as it plays a vital role in public health or safety domains. As a result, such data is associated with a high risk related to potential abuse, manipulation, or unauthorized disclosure. Reducing the amount of high-toxicity data through adequate retention will reduce the impact of a data breach involving such data. Data classification, considering the importance and sensitivity of data, is regarded as a fundamental principle in achieving effective slimming of existing data sets.
2.
Use existing frameworks for data management or governance frameworks to provide government practitioners with requirements and guidance on how to select, design, implement, access, modify, and manage information in governmental information systems sustainably. Applying a framework-based structured approach provides a standardised way of working that eases identifying the current and future relevance of data, including corresponding requirements on storage, retention and protection.
3.
Apply data normalisation to limit Dark Data, the redundancy of the same data stored in multiple sources or locations. This enhances data integrity by avoiding potentially conflicting or corrupted duplicate data sets. Referencing existing data should be preferred over copying that data into another environment.
Data diet to remain data-fit
To tame an organization’s future hunger for data, the expert panel identified several points of attention that contribute to a ‘data diet’ and help to avoid data overconsumption:
1.
Embed data minimisation principles as proposed in legislation and standards. For example, the ISO standard is suggested as it provides government institutes and organizations with a unified baseline on information security requirements. By leveraging the large support base of widely used (mandatory) standards, data minimisation can gain traction effectively. This will expand the scope of the existing data minimalisation principle under GDPR, limited to personal data, to a broader range of data types and categories.
2.
Extend General Data Protection Regulation (GDPR) principles to a broader scope of data. In addition to data minimisation, this also considers the principles of lawfulness, fairness, transparency, purpose limitation, accuracy, storage limitation, accountability, integrity, and confidentiality. As many organizations are familiar with GDPR requirements and principles, they can pursue an expanded scope that also entails non-personal data.
3.
Apply technological solutions to data management. Example cases include automated data retention within system implementations, automated data labeling and mapping on proportionality and purpose, and tracking of explicit consent by ultimate data owners. One of the expert participants in our study suggested leveraging Zero Trust principles [5], such as least privilege, never trust, always verify, assume breach, and "toxic" data and system separation via Protect Surfaces.
Technology Practices for Data Management
Utilising bullet three into technologies, we define the following practices relevant for practitioners to take into account while designing and building technologies:
Database Time-to-Live (TTL) Fields: These fields can be configured with a Time-to-Live (TTL) value, which automatically expires and removes data from the database after a specific period. Tools such as Snowflake’s Time Travel and Databricks’ Delta Lake can automate data version retention and snapshot expiration. This approach maintains lean and up-to-date datasets without manual cleanup interventions and ensures compliance with policies. It automatically expires or deletes records when they exceed a defined age (e.g., “keep financial records for 7 years, then purge”). Vendors that offer this feature include Cassandra, MongoDB (native TTL), RDBMS (cron jobs), Snowflake, and Databricks.
Technologies such as Collibra, Alation, BigID, and OneTrust define, enforce, and audit organization-wide
data retention policies.
Information Lifecycle Management (ILM) and archiving technologies like Veritas Enterprise Vault, IBM Spectrum Protect, Microsoft 365, and Box archive infrequently accessed data to cheaper storage and delete after specified timeframes. Records Management Systems like Laserfiche and FileNet maintain strict record retention schedules, handle legal holds, and automate final disposition. Technical Policy engines and
workflow automation technologies like Terraform, Ansible, Kubernetes, and Airflow schedule and enforce data retention actions as part of infrastructure or application workflows.
These technologies can be set as architectural principles before and during technology builds.
Two roles emerge in this field: The
data architect is responsible for defining tools like we have mentioned above and selecting ways to apply them. Another role is that of data trash engineer. In an earlier
blog, I wrote: "In the role of Data Trash Engineer, you’ll apply analytical rigor and statistical methods to data trash to guide decision-making, product development, and strategic initiatives. This will be done by creating a “data trash nutrition labeling” system that will rate the quality of waste datasets and manage the “data-growth-data-trash” ratio. This role is needed to avoid obese data collection by organisations and to adhere to GDPR regulatory requirements such as data retention schemes".
Do not let FOMO on data in the way of bulking your business.
Organizations today face a powerful tension between collecting enough data to fuel innovation and maintaining responsible data practices that safeguard privacy and security. As Big Tech’s reliance on massive datasets and AI drives a “Fear of Missing Out” on data, evolving regulations like the GDPR underscore the need for purposeful, proportionate collection and robust data governance.
The tension between innovation and compliance has practical implications. Storing “dark data” indefinitely and over-collecting sensitive information increases legal, reputational, and security risks. As high-profile data breaches and costly fines illustrate, unchecked data hoarding can expose organizations to severe consequences.
We propose a dual approach—“data detox” to slim down redundant or excessive existing datasets and a “data diet” to prevent over-collection moving forward. In this article, we limited ourselves in presenting the data fit practices. To equip practitioners, such as policymakers, developers, data governance professionals, and architects, with a repository of Key practices to remain data-fit.
By embedding these practices, such as implementing data minimization principles into existing frameworks, automating retention and deletion practices (with the offered tools), and balancing transparency with privacy concerns, organizations can remain both data-rich and data-fit. In doing so, they reduce legal liabilities, protect their reputations, and strengthen public trust. Ultimately, success lies in moving from a mindset of hoarding “just in case” data to one of mindful, measured data use that supports organizational goals while upholding societal and regulatory expectations.
Conclusion
While data protection regulations (like GDPR) guide why data is collected and how it is used, the rise of AI has ushered in what could be described as “data obesity,” where model performance depends heavily on both the volume and diversity of training data. Much like brass, data retains its value and purpose only so long as it is well-maintained; left unattended, it corrodes and can even become a liability. This leads to a paradox: smaller companies often fail to collect enough data to fuel insights (for business intelligence, marketing, etc.), whereas larger corporations gather vast troves of information, potentially knowing too much. Although the GDPR attempts to regulate data collection using employee thresholds, its effectiveness remains limited. In some respects, this situation is comparable to building muscle mass in the human body: one first needs a foundational level of strength to become more resilient and fit, yet there is a delicate balance between having enough data to thrive and over-collecting to the point of excess.
Sources
T. Kemp, Containing Big Tech: How to Protect Our Civil Rights, Economy, and Democracy, Fast Company Press, 2023.
R. Foroohar, Don't Be Evil: The Case Against Big Tech, 2019.
P. Heidorn, "Shedding Light on the Dark Data in the Long Tail of Science," Library Trends, vol. 57, no. 2, pp. 280-299, 2008.
B. Schneier, Data and Goliath, W.W. Norton & Company, 2015.
Migeon, JH., Bobbert, Y. (2022). Leveraging Zero Trust Security Strategy to Facilitate Compliance to Data Protection Regulations. https://doi.org/10.1007/978-3-031-10467-1_52
Krumay, Barbara and Koch, Stefan, "Data as the New Currency - An Empirical Study Using Conjoint Analysis" (2023). ECIS 2023 Research Papers. 259.https://aisel.aisnet.org/ecis2023_rp/259
MIgeon, J.H. (2024) U.S. Elected Donald Trump As President: What Can We Expect In Tech Regulations? Extracted from https://www.anove.ai/blog-posts/u-s-elected-donald-trump-as-president-what-can-we-expect-in-tech-regulations
FTC Takes Action Against Marriott and Starwood Over Multiple Data Breaches, https://www.ftc.gov/news-events/news/press-releases/2024/10/ftc-takes-action-against-marriott-starwood-over-multiple-data-breaches
This article is an abstract from the full research paper that can be downloaded here: https://doi.org/10.1007/978-3-031-73128-0 Published at Springer Nature Switzerland AG 2024, K. Arai (Ed.): FTC 2024, LNNS 1157, pp. 90–98, 2024.








